
NVIDIA’s Blackwell GPU architecture, particularly the data center-focused GB200 and consumer-oriented RTX 50 series (like the RTX PRO 6000 Blackwell Workstation Edition), has been rigorously benchmarked across various real-world applications, especially in AI/ML and professional visualization.
Here’s a summary of the benchmark results and key takeaways:
1. AI and Machine Learning (LLMs, Training, Inference):
Significant Performance Leaps: Blackwell GPUs show substantial improvements over the previous Hopper architecture, particularly in Large Language Model (LLM) training and inference.
MLPerf Training: NVIDIA Blackwell systems have set new records in MLPerf Training v5.0 benchmarks.
- Llama 3.1 405B Pre-training: Blackwell delivered 2.2x greater performance compared to Hopper at the same scale. A cluster of 2,496 Blackwell chips completed this task in just 27 minutes.
- Llama 2 70B LoRA Fine-tuning: Eight Blackwell GPUs in a DGX GB200 NVL72 system delivered 2.5x more performance than a DGX H100 system.
- GPT-3 175B Training: Up to 2.0x performance improvement per GPU.
LLM Inference: For extremely large models like a 1.8 trillion parameter GPT-MoE, a Blackwell GPU can achieve up to 15x higher inference throughput than an H100 GPU in real-time generation of output tokens.
Efficiency: Blackwell reduces the number of GPUs needed for LLM tasks, offering enhanced scalability, energy efficiency, and reduced operational costs. NVIDIA reports 90% strong-scaling efficiency when expanding from 512 to 2,496 devices, which is phenomenal for large-scale training runs.
Architectural Innovations: These gains are attributed to:
- GB200 Superchip: Combines two Blackwell dies into a single GPU with 208 billion transistors and a 10 TB/s NVLink chip interconnect.
- Second-generation Transformer Engine: With new micro-tensor scaling techniques for FP4 and MXFP6 data types, doubling performance for next-gen AI models while maintaining high accuracy.
- Fifth-generation Tensor Cores: Offering significantly higher AI TOPS.
- Dedicated Decompression Engine: Speeds up data processing by up to 800 GB/s (6x faster than Hopper).
- Increased Memory: Up to 192 GB of HBM3e VRAM on a B200 (a 50% increase over H100) with an aggregate memory bandwidth of 8 TB/s (2.5x H100’s bandwidth).
2. Gaming and Workstation Performance:
RTX PRO 6000 Blackwell Workstation Edition: Benchmarks for this workstation-grade Blackwell GPU have started to emerge, showing its capabilities in professional applications and some gaming tests.
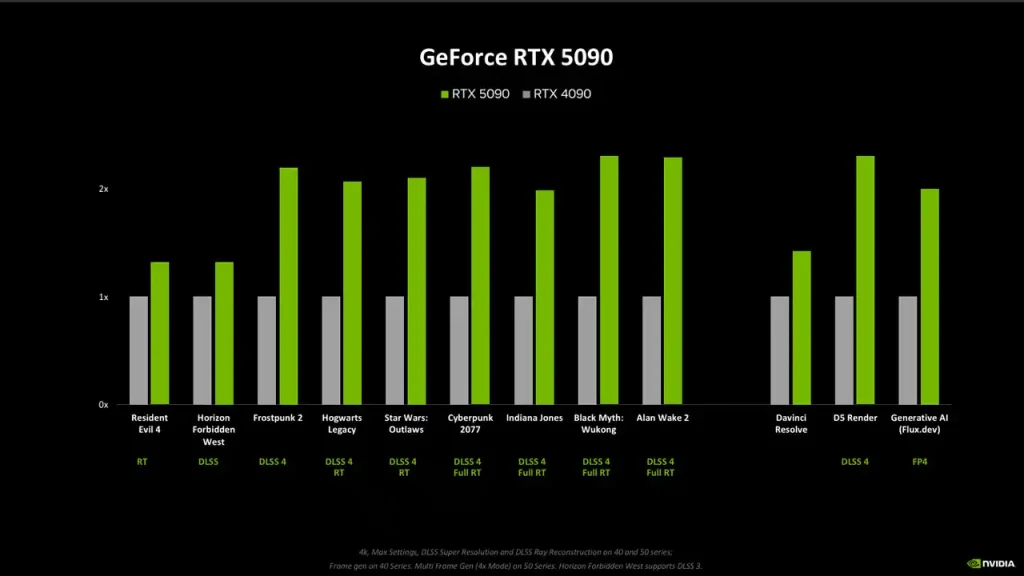
- Gaming: While the primary focus of these professional cards isn’t raw gaming performance, reviews like Gamers Nexus’s testing of the RTX PRO 6000 Blackwell Workstation Edition show its performance in titles like Dragon’s Dogma 2, FFXIV Dawntrail, Starfield, Resident Evil 4, Black Myth Wukong, Dying Light 2, and Cyberpunk 2077. These benchmarks provide insights into its general rendering capabilities, including ray tracing.
- Professional Applications: The RTX PRO 6000 Blackwell Workstation Edition is being benchmarked in applications like Autodesk VRED 2026, demonstrating its enhanced rendering, visualization, and simulation capabilities, delivering increased speed and quality.
Consumer RTX 50 Series (Expected): For the mainstream gaming segment, the Blackwell architecture (e.g., in the expected RTX 5070) is anticipated to bring performance gains from:
- Neural Shaders: Optimized for AI rendering.
- 5th Gen Tensor Cores: For better DLSS 4 performance.
- 4th Gen RT Cores: For improved ray tracing.
- GDDR7 Memory: Providing significantly faster bandwidth.
- DLSS 4 with Multi Frame Generation: This AI-powered technology is a major contributor to perceived frame rate increases.
- While raw rasterization IPC might see modest gains, the overall performance uplift is expected to be significant due to these combined factors.
3. Microarchitectural Analysis:
Researchers are conducting microbenchmarking studies to understand the underlying performance features of the Blackwell architecture. These studies compare Blackwell (e.g., GeForce RTX 5080) with Hopper (H100 PCIe) to reveal insights into latency, throughput, cache behavior, and scheduling details. They are also investigating power efficiency and energy consumption under varied workloads.
In summary, NVIDIA Blackwell GPUs are demonstrating substantial real-world performance improvements, particularly in AI and machine learning workloads, driven by significant architectural advancements in transistor count, Tensor Cores, Transformer Engine, memory bandwidth, and interconnect technologies. For professional applications, initial benchmarks show strong performance in demanding visualization and simulation tasks. While consumer gaming benchmarks are less prevalent for the workstation variants, the underlying architectural improvements point to notable performance gains for future gaming GPUs.

